A platform survey: interface language support by widely-used websites and mobile apps
A platform survey: interface language support by widely-used websites and mobile apps


Oxford Internet Institute, University of Oxford. With generous support by Whose Knowledge? We extend our gratitude to Dr Mandana Seyfeddinipur for her invaluable guidance.
Oxford Internet Institute, University of Oxford. With generous support by Whose Knowledge? We extend our gratitude to Dr Mandana Seyfeddinipur for her invaluable guidance.
Introduction
A common theme weaves through our report: many apps and websites are not available in the thousands of languages people around the world speak everyday. As a consequence, every day billions of people around the world are affected by a kind of language exclusion. And yet among technology experts there is often little awareness about the pervasiveness of the problem. This in part reflects that all of us only see a tiny part of the picture: there currently are no publicly available surveys that can give us a basic impression of the scale of such language exclusion among the most widely used digital platforms. To address this knowledge gap we present a first platform survey that collects and analyses the interface languages supported by major digital platforms in an attempt to improve our collective understanding of online language inclusion and exclusion.
Many of the essays in this report testify that a lack of language support is often the most immediate barrier that leads to forms of digital exclusion, or that forces people to switch languages and even cultural frames in order to access certain digital affordances. In some cases this means there is a lack of digital content in the user’s own language – for example, in this report we also consider the examples of Google Maps and Wikipedia. But the first barrier is often more basic: the user interfaces of many digital platforms are typically only available in a limited number of languages. In some ways this is understandable – the translation of user interface elements into a new language requires significant effort, and platform providers need to make some hard choices about which languages they should prioritise over others. But as a direct consequence, people who do not speak any of the languages supported by a platform may find themselves locked out solely on the basis of their language.
In an effort to document the pervasiveness of this problem we have reviewed the language support of a few dozen widely used websites, Android apps, and iOS apps to understand which parts of the internet are accessible to which global populations on the basis of their language, and on the basis of this survey we have tried to estimate which parts of the world are potentially left out. In our selection we placed a specific focus on widely used platforms relating to knowledge access and communication, including key knowledge and information portals such as Google and Wikipedia, platforms for self-guided language learning, and many of the messaging and social media platforms used around the world today. Do these platforms provide interface support for particular languages but not others? Which languages are more or less widely supported? And which populations are potentially excluded as a result of the decision to not support their language?
Our platform survey provides us with a first general impression of the pervasiveness of the issue; however, relative to the rich ecology of platforms, we still consider it quite modest in scope. Now that the internet is an extension of so many aspects of our lives, it takes as many shapes and forms as any other aspect of human existence. People’s internet use varies widely. Or to put it more succinctly, there are many internets, not just one – and it is thus impossible to conclusively determine what languages are supported by “the internet”. It depends on where you look.
Before we summarise our findings it is important to state that by necessity, our work relies on data sets and methods that introduce inaccuracies and potential misrepresentations, particularly when it comes to assessing the complex and nuanced relationships between individual languages, or when trying to estimate language population sizes and language geographies. As a result we may be confronted with claims that are disagreeable on a conceptual or political level. We discuss the key challenges and nuances of our methods in the text, starting with a detailed critique in our methodology section. However, in the absence of better sources these are the best estimates we have, and they can at least provide us with a basic set of general impressions, and a framework on which to build further work.
Summary of findings
Overall we find that language support is highly unequally distributed. Major web platforms like Wikipedia, Google Search, and Facebook are at the forefront of language support, each offering interface support for more than 100 languages. Among them, the non-profit Wikipedia stands out as the most comprehensively translated platform by far, with a total of almost 300 supported interface languages, followed by Google Search with 150 languages. Among messaging apps, the open source mobile app Signal has the most comprehensive language support, having been translated into almost 70 languages on Android, and more than 50 on iOS. That said, many of the other platforms we surveyed only support around 10-30 of the thousands of languages spoken today. Most platforms focus their support on a small number of the more widely spoken languages, and the majority of languages spoken today remain unsupported.
We can see some common patterns in how this affects different language communities around the world. A small set of particular languages tend to be very widely supported by the platforms we surveyed, including certain European languages such as English, Spanish, Portuguese, and French, and certain Asian languages such as Mandarin Chinese, Indonesian, Japanese, and Korean. Major languages such as Arabic and Malay are less well supported than may at first appear, in great part due to their high linguistic diversity. Other languages spoken by tens to hundreds of millions of people are highly unequally represented in terms of both interface support and content availability. For example, the vast majority of African languages are not supported as an interface language by any of the platforms we surveyed, and as a result more than 90% of Africans need to switch to a second language in order to use the platform – which for many will mean a European-colonial language. Many Africans speak English, French or other colonial languages, yet not everyone will necessarily agree that these are “African languages” – rather than languages spoken in Africa as a result of its colonial history. In South Asia, almost half of the platforms we surveyed do not offer interface support for any regional language, and major South Asian languages such as Hindi and Bengali, spoken by hundreds of millions of people, are not as widely supported as we might expect. Support for South-East Asian languages is similarly mixed: while Indonesian, Vietnamese, and Thai tend to be very well supported by the platforms we surveyed, most other South-East Asian languages are not.
Overall this leads to significant digital exclusion of billions of people on the basis of their language. By this we mean a potential exclusion of access for those who do not speak certain languages, as well as marginalisation – that is, a form of exclusion resulting from being made invisible on the platform, of being declined an opportunity to represent one’s language culture, and of having to adapt to a foreign language culture in order to participate. In this sense, even Wikipedia and Google Search still potentially exclude as many as a billion people, and other platforms exclude as much as half the human population, and in some cases even more. People in these excluded communities have to be able to speak a second (major) language in order to be able to use and participate in these platforms.
The data collected for this survey are available for download in the following link: gitlab.com/stil-report/stil-2020-data/
Methodology
Before we discuss our findings in more detail we will briefly outline our methodology. In principle it is relatively straightforward to determine which interface languages are offered by a particular platform, yet our analysis also requires dealing with some of the subtleties of language classification.
Platform selection
In total we surveyed 11 websites, 12 Android apps and 16 iOS apps. We chose a selection of widely used platforms that specialise in the collection and sharing of knowledge, in particular those that seek to cater to global audiences.
We grouped these platforms into four broad categories:
- Knowledge access (knowledge and information platforms, including search engines): Google Maps, Google Search, Wikipedia, YouTube.
- Language learning (self-guided language learning platforms): DuoLingo, and the education platforms Coursera, Udacity, Udemy.
- Social media (public-facing social media platforms): Facebook, Instagram, Snapchat, TikTok, Twitter.
- Messaging (private and group messaging): imo, KakaoTalk, LINE, LINE Lite, Messenger, QQ, Signal, Skype, Telegram, Viber, WeChat, WhatsApp, Zoom.
These categories are not perfect. Apps like Telegram and Snapchat or websites like YouTube arguably sit across multiple categories, and we encourage you, our readers, to bring your own interpretations as you review our findings.
It is also important to acknowledge that this selection has a distinct Western bias, which is an inadvertent consequence of our selection criteria. We can illustrate this quite well in the case of language learning platforms: the four US-based platforms included here are the only large language learning platforms we could identify that are focused on self-guided learning across all ages. There are countless other widely used education platforms such as KnowBox, BYJU, Yuanfudao and others that originate in India, China, and elsewhere, however they are typically more focused on supporting formal education for children and teens, and they cater to a particular national curriculum.
In other words, in focusing on larger platforms that cater to self-guided knowledge access, we have introduced a selection bias of platforms that originate in the wider context of Western and Silicon Valley startup culture.
To somewhat soften this selection bias we have made an effort to look at the broader platform ecology of messaging apps in more depth – here we also include widely used apps that are not part of the Western canon, they are included in the selections above.
In practice, as we have just seen for education platforms, many of the world’s language communities we talk about in this report will have their own individual platform ecologies. While this initial platform survey is by necessity more limited in scope, it is our hope that we can examine some of these regional platform ecologies in more depth in future reports.
Data collection
A range of different approaches was needed to collect information about language support offered by websites and mobile apps.
Websites typically display a list of supported languages as part of a user interface element, such as a language dropdown in a page footer. This means we were able to extract lists of supported languages from HTML or Javascript sources. Many websites identify languages by ISO language code in their code, sometimes including a territory suffix which allowed us to identify language variants with greater specificity.
For our survey of iOS apps we relied on the language list for each app as provided in the Apple app store, which identifies languages by name only, and we mapped these language names to ISO language codes. The app store does not include any territory qualifiers in their list of supported languages. As a result it is possible that we are under-estimating the iOS coverage of certain languages with major regional variants, such as Kurdish, Thai, Sotho, and others.
The identification of supported languages was more challenging for Android apps; here we needed to download and decompile application binaries in order to inspect their translation files. These are typically recorded in a standard format, and languages are identified by a localisation code, which is a combination of both language and territory codes. We disregarded any translations that were provided by third-party libraries embedded in the application, and only considered translations that related to the main user interface of the app itself. We further identified and disregarded instances of partial translations that only covered a small subset of the user interface: a mobile app interface can frequently involve more than 1,000 individual words and phrases, and we reviewed and disregarded translations that only covered 100 of these or less. Unfortunately we were unable to analyse the Android version of Facebook Messenger in this manner, given its binary is heavily obfuscated to prevent reverse engineering, which means we are unable to access its list of interface languages.
A summary of language counts per platform is shown in Table 1.
Number of supported interface languages per surveyed platform.
| Type | Category | Name | Number of languages |
|---|---|---|---|
| Website | Knowledge access | Google Maps | 74 |
| Website | Knowledge access | Google Search | 150 |
| Website | Knowledge access | Wikipedia | 286 |
| Website | Knowledge access | Youtube | 83 |
| Website | Language learning | Coursera | 10 |
| Website | Language learning | DuoLingo | 23 |
| Website | Language learning | Udacity | 10 |
| Website | Language learning | Udemy | 17 |
| Website | Social media | 106 | |
| Website | Social media | 47 | |
| Website | Messaging | Zoom | 11 |
| Android App | Social media | 91 | |
| Android App | Social media | 42 | |
| Android App | Social media | Snapchat | 22 |
| Android App | Social media | TikTok | 31 |
| Android App | Social media | 19 | |
| Android App | Messaging | LINE | 10 |
| Android App | Messaging | LINE Lite | 19 |
| Android App | Messaging | Signal | 69 |
| Android App | Messaging | Telegram | 8 |
| Android App | Messaging | Viber | 48 |
| Android App | Messaging | 3 | |
| Android App | Messaging | 58 | |
| iOS App | Social media | 31 | |
| iOS App | Social media | 27 | |
| iOS App | Social media | Snapchat | 27 |
| iOS App | Social media | TikTok | 40 |
| iOS App | Social media | 33 | |
| iOS App | Messaging | imo | 40 |
| iOS App | Messaging | KakaoTalk | 15 |
| iOS App | Messaging | LINE | 17 |
| iOS App | Messaging | Messenger | 27 |
| iOS App | Messaging | 1 | |
| iOS App | Messaging | Signal | 53 |
| iOS App | Messaging | Skype | 39 |
| iOS App | Messaging | Telegram | 15 |
| iOS App | Messaging | Viber | 33 |
| iOS App | Messaging | 18 | |
| iOS App | Messaging | 39 |
Ethnologue
In our analysis we rely on the population estimates, regional classification of language origin, and other basic information about languages provided by Ethnologue, a global survey of the thousands of active languages in use today (Eberhard, Simons, and Fennig 20201). Until recently, Ethnologue offered free access to its information about the 200 most widely spoken languages, and we use this as a reference data set. It includes widely spoken languages such as English, Mandarin Chinese and Hindi, each spoken by billions or hundreds of millions of people, as well as more regional languages that are spoken by millions. According to Ethnologue, this list of 200 languages captures the primary languages for almost 90% of the human population. However, these languages are only a fraction of the estimated 7,000 languages spoken today, and as a result many local language communities unfortunately cannot be fully represented in our survey.
A central characteristic of the Ethnologue data set is that it catalogues spoken languages rather than written language. While some languages do not make a clear distinction between the spoken and written forms, for many languages there are significant differences between them. For example, the many Arabic language dialects are built on oral language traditions and often do not have their own separate written forms. Instead, user interfaces are commonly offered in Modern Standard Arabic, which can diverge quite significantly from one’s respective spoken dialect. For Arabic, the Ethnologue 200 includes the standard written form, as well as 18 regional spoken variants such as Egyptian, Moroccan, Sudanese, Tunisian, and Hadrami Arabic.
One immediate effect of our reliance on the Ethnologue 200 is that our survey cannot properly do justice to regions that are characterised by a wealth of highly local indigenous languages, such as the native languages of the Americas, and many Austronesian languages of the Pacific. The Ethnologue 200 lists only two American languages, Haitian Creole and Guaraní, and one language of the Pacific, Tok Pisin. The more widely spoken languages of these regions like English, Spanish, and Portuguese are classified as “European” languages according to Ethnologue. As a result, many of the languages of the Americas and the Pacific are not present in our survey. This is particularly important to keep in mind in the context of Wikipedia’s recent focus on supporting marginalised languages – unfortunately many of these pioneering efforts will not be evident in our results.
Finally, it is highly debatable whether we should take the numbers provided by Ethnologue at face value, particularly if we consider the many practical challenges involved in producing such a comprehensive and world-spanning language survey. Yet, despite its many shortcomings it is the best information source about language use we have available today.
Language comparison
A central challenge in our survey is that languages come in a wealth of dialects and other variants, and the lines of distinction between these language variants are not always very clear. For example, some of the 12 Chinese languages listed in the Ethnologue 200 are closely related, and while speakers of these languages may therefore be able to understand each other with some effort, this is not true for all cases. The Ethnologue 200 lists language dialects and language variants for many large and small languages, including Arabic (as mentioned above), Malay (Indonesian, Minangkabau, and others), Spanish (Latin American Spanish), English (British, American, Australian, and Indian dialects), French (Canadian dialect, Creole languages), and many more.
With this in mind, we make an effort to estimate whether native speakers of a particular language will be able to use interfaces in another, depending on how related they are. For example, a native speaker of Brazilian Portuguese will be able to use an interface that is offered in (European) Portuguese without much effort, while a Moroccan speaker of Maghrebi Arabic might be slightly unfamiliar with the Modern Standard Arabic commonly offered by many online platforms.
In an attempt to capture such relationships in our survey we use a language matching method offered by the Unicode Consortium standards body that tries to express such relationships between languages and their language variants as a simple measure of language distance, on the basis of language family, written script or alphabet, and language territory (Unicode 20202). We rely on an implementation of the language matching process provided by the “langcodes” Python library.
Using this as a basis we attempt to estimate whether the language variant spoken by a particular population group is supported by the platforms we surveyed. In principle this method offers us an estimate of the resulting language distances to a relatively fine degree, however in practice we only consider three cases:
- Fully supported (Unicode language distance 0-9): when the primary language of users is directly supported as an interface language.
- Potentially supported (Unicode language distance 10-14): when the primary language of users is not supported, however a language or language variant is offered that they may be able to understand, for example because it is a dialect of their primary language.
- Not supported (Unicode language distance 15 or greater): when users are unsupported because their primary language or the variants of it are not offered as an interface language.
As one might imagine, any such attempt to map the distance between languages is confronted with all the complexities and contradictions of human language culture, and we will raise several conceptual issues with this measure in our discussion of results. For example, according to this measure English is regarded as a suitable user interface substitute for many African languages in cases where they are not supported directly. This might reflect the way language is used in practice – no doubt many speakers of African languages may be able to speak English. Yet, from a linguistic, cultural, and political perspective we would not consider an English-language interface to be a successful instance of African language support. In other words, when assessing certain groups of languages the Unicode language matching algorithm will be insufficient for a complete assessment, and we always also need to review individual language relationships in order to make a proper assessment.
Downloading our data
An integrated and downloadable data set is available for download on Gitlab.
The results
We will first discuss the results of our survey in a general sense, and as part of this we will try to estimate the scale and scope of language inclusion and exclusion. We will then discuss our survey results for African and South- and Southeast Asian languages in more detail. We will close with a broader discussion of our findings.
How comprehensively are platforms translated?
The visualisation in Figure 1 summarises the number of interface languages that are supported by each of the platforms we surveyed. The chart shows that major web platforms like Wikipedia, Google Search, and Facebook are at the forefront of international language support: they each offer interface support for more than 100 languages. We will see throughout the survey that these three platforms in particular tend to focus a lot of effort on supporting a large number of languages. In the case of Google and Facebook we suspect that this is in part made possible by the significant economic scale of these organisations, and their ambition to provide services to people around the world. And yet, the non-profit Wikipedia stands out as the most comprehensively translated platform by far, with a total of almost 300 supported interface languages.
Beyond these three leading platforms we see a wide spectrum of outcomes, where many of the platforms we surveyed still support dozens of languages, though many support only a few. At the bottom end of our sample we see the messenger app QQ, which specifically targets speakers of Mandarin Chinese as their primary market, and which does not support any other languages. In contrast, many messaging and social media platforms support dozens of languages, in particular Facebook’s Whatsapp, the free VoiP and messaging app Viber, and Microsoft’s Skype. Yet it may be a surprise to some that the open source app Signal has the most comprehensive language support among messenger apps, being offered in almost 70 languages on Android, and more than 50 on iOS. We think this is a remarkable achievement, particularly since Signal does not benefit from the significant resources available to companies like Facebook or Google, or even non-profits like Wikipedia.
By comparison, the language learning websites we looked at like Duolingo, and the education platforms Coursera and Udemy, are comparatively constrained in their language support – each of them only supports a relatively small number of languages. We suspect that this is because it would not be sufficient to only translate their interfaces. In contrast to messaging apps (where you just need to translate interface elements), language learning platforms would need to translate their full curriculum in order to be accessible to broader audiences, which requires significantly more effort.
In certain cases, our platform survey also allows us to compare language support by the same platform across its mobile and web versions. We can make this comparison for Facebook, for Facebook Messenger (which on the web is part of Facebook itself but on mobile is a separate app), and for Twitter. In these three cases, the website versions support more languages than the mobile versions. We can also see that Facebook has broader mobile language support on Android than on iOS, while Twitter has better mobile language support on iOS. (Unfortunately we were unable to survey Facebook Messenger on Android, for the reasons discussed in our methodology section.)
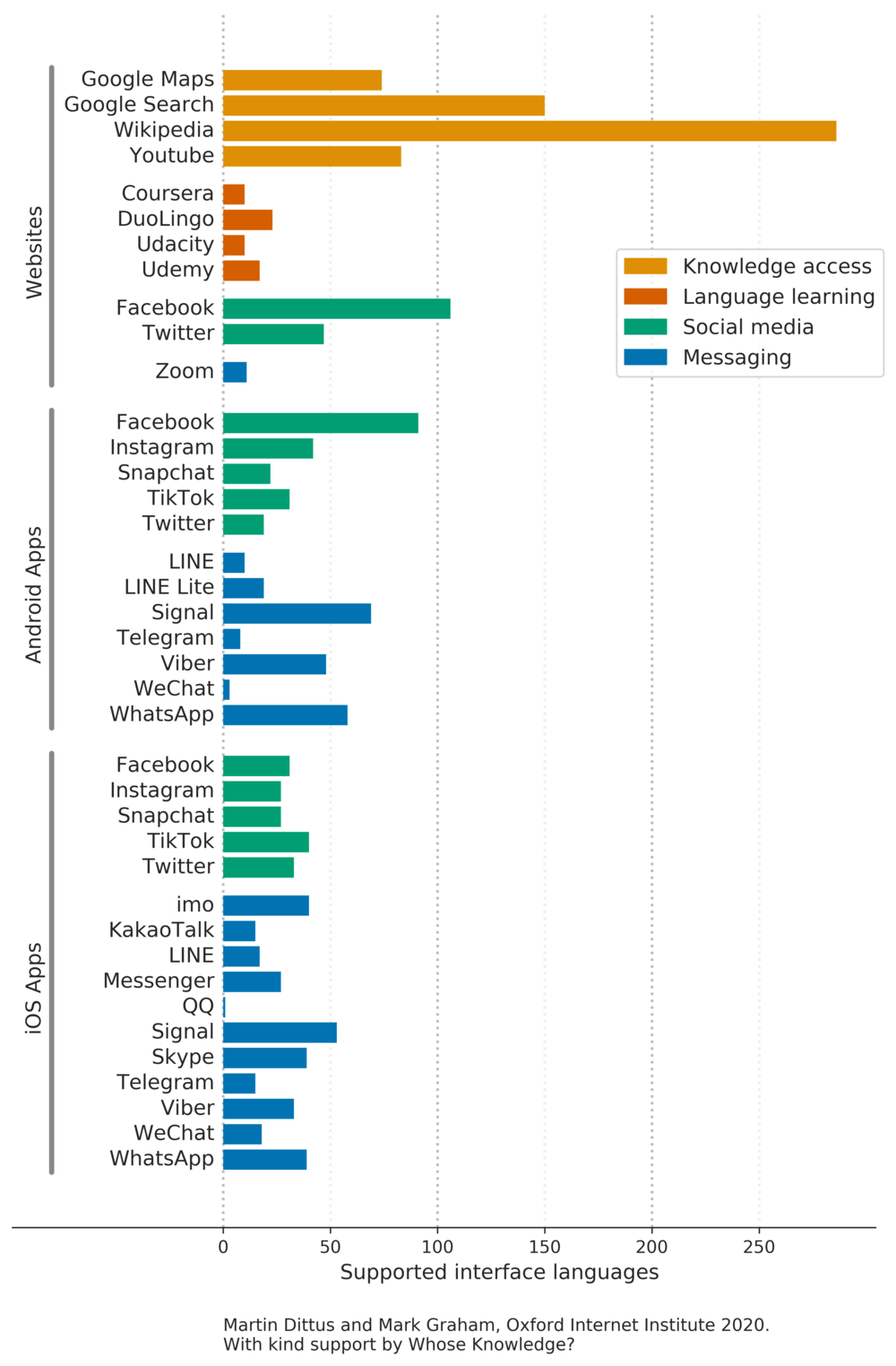
Support for widely spoken languages
While these numbers are interesting in some ways, in other respects they are potentially misleading – and they do not allow for an even comparison. For example, Facebook offers three English user interface variants for their website: American and British dialects of English, but also what they call “Upside Down” English (uʍop əpısdՈ) – which appears to be offered for reasons of playfulness rather than a need to support a particular language community. Similarly, Google Search offers at least five such playful interface options, including the made up languages Klingon, Pirate English, and Swedish Chef. These inclusions are interesting in some ways, however none of them are spoken in (everyday) practice. Finally, a simple count of a platform’s supported languages does not tell us much about the impact of any omissions – it does not give us a sense of how many people are potentially excluded.
To avoid these issues, we instead assess to what extent a given platform provides interface support for the world’s most widely spoken languages. As a reference data set we use the Ethnologue survey of the world’s 200 most widely spoken languages, as described above. We further rely on the Unicode language matching process to determine whether a user interface language offered by a particular platform will be understood by speakers of any of the 200 Ethnologue languages, as discussed above.
This process of language comparison is not without its complications – we have already hinted at some of the nuances and pitfalls of this language distance measure in our methods section, and in our discussion of results we will raise some further issues that affect our interpretation of outcomes, and provide further context where needed. In general we would say that these measurements and their visualisations can give us a broad impression of the issue, but we also need to know the specific language relationships in order to really understand what is happening. This is especially necessary in the context of African languages, where the Unicode language distance measure falls short. These issues should act as reminders of both the strengths and the limitations of such simplistic quantitative analyses when examining the complex social and political circumstances of human existence.
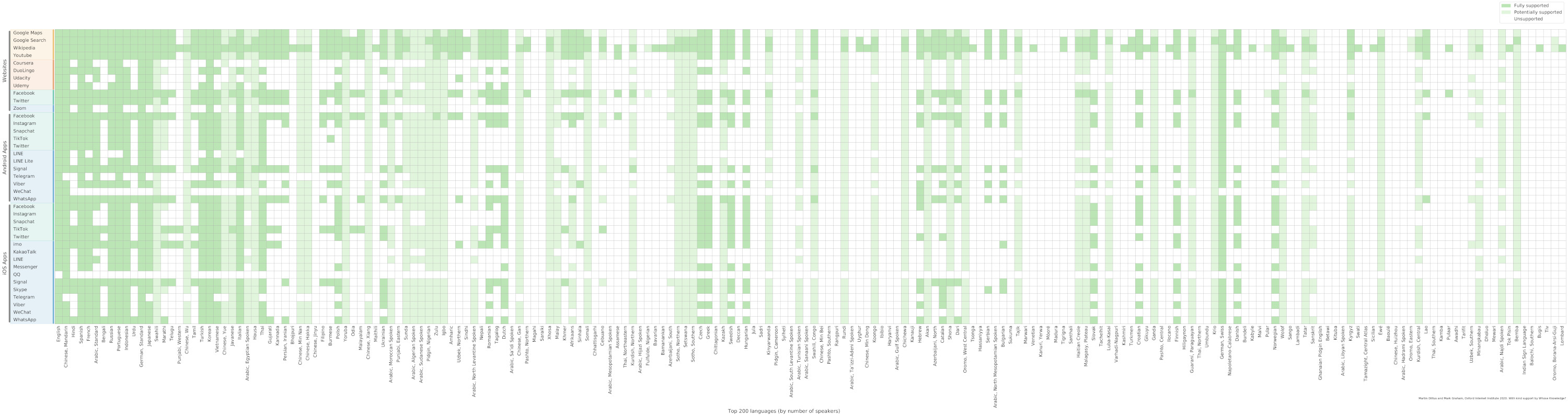
Using these methods we can now determine which of the platforms offer support for each of the 200 languages. We show this in Figure 2 as a matrix, with platforms listed vertically in the same order as before, and languages listed horizontally, ranked by the respective number of speakers (including second-language speakers). We offer two versions of the matrix; an easily readable version in Figure 2 that shows the 40 most widely spoken languages, and a more comprehensive version in Figure 3 that covers all 200. Both charts show the most widely spoken languages on the left, with billions or hundreds of millions of speakers, and on the right we have smaller languages spoken by millions of people – ranked 40 is Odia, a South Asian language spoken by almost 40 million people, and ranked 200 is Lombard, an Italian language spoken by almost four million people.
The horizontal green stripes indicate platforms that support a wide range of languages. As expected, we can see that Wikipedia, Google, and Facebook support the largest share of languages in the Ethnologue 200. Wikipedia supports almost two thirds of the languages, Google Search almost half, and Facebook has interface support for about a third. By comparison, most other platforms only support a fraction of the most widely spoken languages – Signal and WhatsApp support about a quarter of the languages, while most of the remaining messaging platforms typically only support between 10-20% of the 200 most widely spoken.
Vertical green stripes in the visualisations represent languages that are supported by a wide range of platforms. Overall we also see a gradual drop in language support as we go down in Ethnologue rank: the plot is visually more dense on the left than the right, which means languages spoken by more people tend to be better supported by the platforms we surveyed.
The visualisations also already give us a sense of some important gaps in platform language support – these are visible as vertical blank stripes, or languages that don’t tend to be as well supported as other languages of a similar size. For example, among the 10 most widely spoken languages, Hindi and Bengali are often less well-supported than the others, despite collectively representing a major population of about a billion people. (We consider these, together with other South Asian languages such as Urdu, Punjabi, Marathi, and Telugu, in more detail below.)
Just as strikingly, the chart suggests that African languages are often not very well-supported by many platforms. We can see the major African languages Swahili, Hausa, and Yoruba in the top 40, each marked as “potentially supported”. This classification is misleading – in all three cases, the Unicode language matching algorithm offers us English as a suitable substitute language in order to achieve this “partial support”. In other words, when assessing African languages we need to review the true language relationships in order to make a proper assessment. And from the broad vantage point of these three major African languages, support for African languages is actually quite poor. (Again, we will discuss African languages in more detail below.)
We can also see partial language support indicated for various Chinese language variants – for which the Unicode language distance measure offers us Mandarin Chinese as a potentially suitable replacement – and Javanese for which it offers Indonesian. In all these cases, speakers of the respective language may not actually be able to use interfaces in the suggested alternative languages, however there is some likelihood that they do speak it as a secondary language.
By comparison to most of the languages discussed so far, European languages such as English, Spanish, Portuguese, French, German, and Italian tend to be very well-supported by most platforms – which in some ways is understandable because they are widely spoken around the world, in some cases due to their colonial histories. Similarly, East- and South-East Asian languages such as Korean, Japanese, Indonesian, Thai, and Vietnamese are very well supported, in part because they are widely spoken. However in the context of the absence of support for other languages that might be even more widely spoken, such as Bengali or Urdu, we are starting to see the first potential instances of digital language marginalisation.
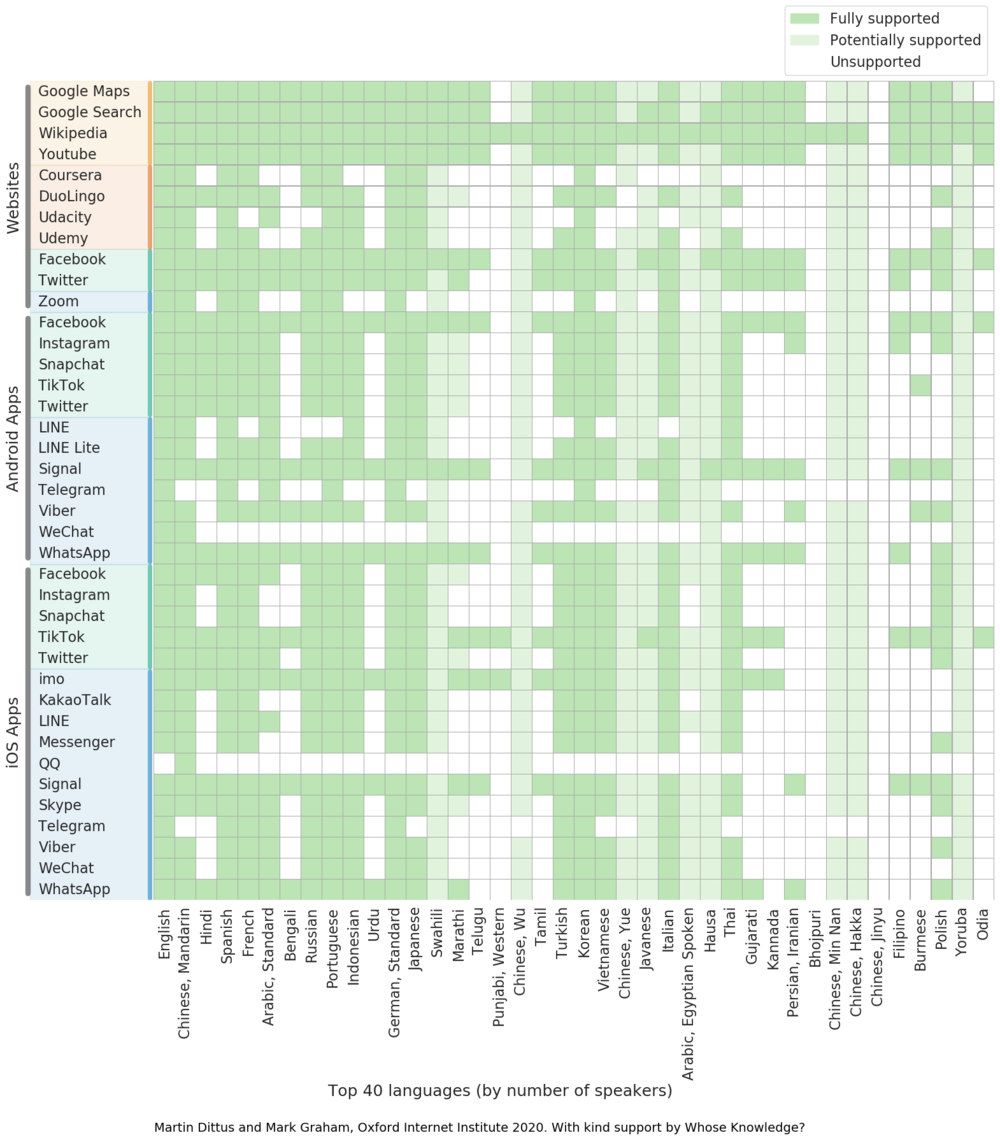
Language support across global regions
Now that we have looked at the distribution of language in broad strokes we want to understand better which groups of languages tend to be more or less well-supported; again, starting with a broad geographic perspective. To what extent do platforms offer more or less support for languages that originate in particular regions? For example, are South Asian languages as well supported as European languages on the platforms we surveyed?
Ethnologue offers an identification by continent (“Area”) and subcontinent (“Region”) for each of their top 200 languages. Based on these we can offer some broad estimates for how many websites or apps offer interface support for at least one language that originates in each global region.
Unfortunately this geographic classification of languages works better for some languages than others. Notably, languages of European origin are classified as “European”, even if they are widely spoken in other places around the world – such as Spanish, which is widely spoken in South America and in parts of the Pacific region. Further, many of the regional languages of the Americas and the Pacific are not included in the Ethnologue 200, likely because they are spoken by smaller population groups – it only lists Haitian Creole and Guaraní for the Americas, and Tok Pisin for the Pacific. As a result we can offer a geographic perspective on platform language support for Europe, Africa, and Asia, however we unfortunately do not have sufficient information to be able to speak about the languages of the Americas and the Pacific.
The data in Table 2 compares the current language support by continent, showing the number of platforms that have direct interface support for at least one language that originates in that continent, expressed in absolute numbers (number of websites or apps) and as percentages (share of all websites and apps in the analysis). The table makes obvious the lack of Ethnologue coverage in the Americas and the Pacific region, but also that the few languages listed for these regions are largely unsupported by most websites or apps. African languages fare better, but are still often unsupported – especially on mobile apps. By comparison, Asian and European languages are the best supported by the platforms in our survey, and almost all surveyed platforms support at least one language from each of these regions. Platform support for European languages is below 100% due to our inclusion of the QQ messenger which is only available in Mandarin Chinese, and does not support any other languages.
| Continent | Number of platforms | Share of platforms |
|---|---|---|
| Americas | 3 | 11.5% |
| Europe | 25 | 96.2% |
| Africa | 8 | 30.8% |
| Asia | 26 | 100.0% |
| Pacific | 1 | 3.8% |
Table 3 breaks these numbers down at subcontinental level, this time excluding the Americas and the Pacific.
| Subcontinent | Number of platforms | Share of platforms |
|---|---|---|
| Western Europe | 25 | 96.2% |
| Northern Europe | 25 | 96.2% |
| Southern Europe | 25 | 96.2% |
| Eastern Europe | 24 | 92.3% |
| Western Africa | 4 | 15.4% |
| Northern Africa | 1 | 3.8% |
| Southern Africa | 7 | 26.9% |
| Eastern Africa | 7 | 26.9% |
| Middle Africa | 7 | 26.9% |
| Western Asia | 23 | 88.5% |
| Central Asia | 8 | 30.8% |
| Southern Asia | 15 | 57.7% |
| South-Eastern Asia | 23 | 88.5% |
| Eastern Asia | 26 | 100.0% |
We can see that within Europe, Eastern European languages are potentially less well-supported than other European languages. This shows that there is potential marginalisation even within relatively well-supported regions, a barrier for those who do not speak certain languages, and a lack of capacity to represent one’s own language culture.
The Ethnologue 200 includes dozens of African languages. Many of these are Arabic dialects spoken in North Africa, and we find that none of these Arabic dialects are directly supported by any platform, with the notable exception of the Egyptian Arabic language version of Wikipedia. Instead, platforms generally only offer interface support in Modern Standard Arabic, which is its own distinct dialect again. Language support for other African languages varies by region, which we will discuss in more detail below.
Within Asia, we can see that Central Asian languages are not well-supported at all. Ethnologue lists Uzbek, Kazakh, Tajik, Turkmen, and Kyrgyz, some of which are supported by Wikipedia, Google and Facebook, but most of which are generally unsupported by most of the platforms we surveyed. By comparison, South Asian languages (the languages of India and the surrounding region) are somewhat better supported.
This complex set of outcomes illustrates that if we want to examine platform coverage in particular global regions we need to take time to understand their particular language geographies. These basic summary statistics can only ever give us a rudimentary first impression, given their relative high level of abstraction.
With respect to our initial questions we can broadly see that many East Asian and European languages are better supported than other languages, at least from a high-level vantage point. Comparing across platform types we can also see that Android apps tend to have better language support for African and South Asian languages than iOS apps, while South East Asian languages tend to be well supported on both mobile platforms. In general, the data suggests that many languages of the Global South are less well supported than this. However, we also see suggestions of a lack of language support within well-supported regions – languages of Eastern Europe are potentially less well-supported within generally well-supported Europe, and the languages of Central and South Asia are less well supported than other regions of Asia. This kind of “nested exclusion” suggests the presence of a systemic logic of exclusion rather than a simple Global North-South divide; it may be the result of market forces bearing on the decision of whether to spend money supporting particular markets.
Excluded populations
How many people are potentially excluded or marginalised by this lack of interface language support? It is hard to answer this question in a general sense, as many people speak multiple languages. However, we can ask: how many people would need to switch to a second language in order to be able to use one of these platforms, because their primary language is not supported?
We can attempt an answer using Ethnologue’s population estimates for every language, which accounts for 6.2 billion people globally – this is the sum of all first-language speakers of the top 200 languages, according to Ethnologue. (By comparison, the global population is currently estimated at 7.9 billion people.) In other words, using these population estimates we can estimate the number of people whose first language is not supported by a given platform, and who are potentially excluded or marginalised on the basis of that language. To complement this picture we can further estimate the number of people who might be potentially included because an additional language is available to them.
Figure 4 presents these numbers, providing an estimate for each platform of the global population that is potentially excluded by the platform on the basis of their first language.
These estimates show how striking Wikipedia’s achievement is. We have already seen that it supports the widest range of languages among all surveyed platforms, and we can see here that probably excludes the smallest number of people on the basis of their first language. Just under a billion people are likely unable to access Wikipedia because their primary language is not supported as an interface language. This estimate gives us a first sense of the general scale of the problem – compared to other platforms this is a striking achievement, however Wikipedia still probably excludes a significant number of people on the basis of their language.
As we might expect, Google and Facebook also achieve respectable outcomes, although they potentially exclude twice as many people on the basis of their first language – between two and three billion people might not be able to access Google or Facebook in their first language.
Most of the remaining platforms probably exclude more than two billion people. In other words, we estimate that several billion people would need to be able to speak a second language in order to use most of the apps and websites we surveyed.
Based on these observations we can say that at least a quarter of the world’s population (two billion of almost eight billion people) is potentially excluded by most of the surveyed platforms on the basis of their primary language, and many platforms exclude as much as a third or even half the human population.
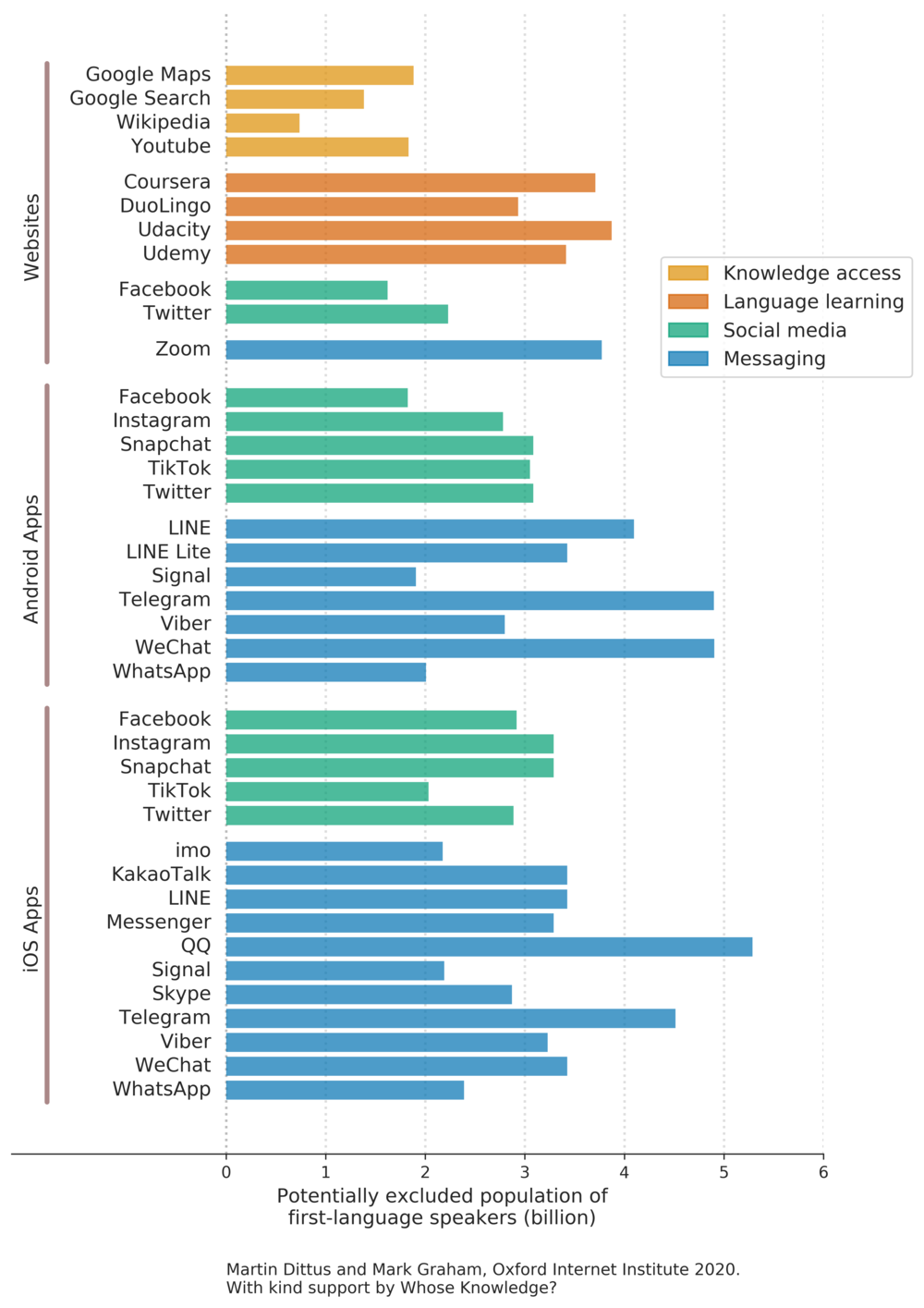
Commonly excluded languages
Which languages are among the least well-supported? It is impossible to determine a clear point at which a particular language can be considered excluded, however as a first estimate we can simply identify those languages that are not supported by either of the three major platforms Google Search, Wikipedia, or Facebook (on web or mobile.) Table 4 ranks the 20 most widely spoken languages in the Ethnologue 200 that are unsupported by all three platforms.
In total, almost 60 of the 200 languages in our sample are not supported as an interface language by Google, Wikipedia, or Facebook ; accounting for an estimated half a billion people.
These excluded languages originate in two regions: Africa and Asia. On the one hand, 19 of the 64 African languages in the Ethnologue 200 are not supported by all three platforms, accounting for more than 100 million first-language speakers. Among them, many local Arabic dialects, but also Western African languages such as Jula and Ibibio – each with millions of speakers. Additionally, 29 of the 103 Asian languages in the Ethnologue 200 are not supported by all three of the platforms, accounting for almost 400 million first-language speakers – of which 22 languages are in Southern Asia ( representing more than 200 million speakers). Among these commonly excluded languages are Magahi, Saraiki, Chhattisgarhi and two dozen others, each with millions of speakers.
These are sobering reminders of how far we have yet to go: in total, almost a billion people need to be able to speak another language in order to be able to use any of these major platforms. We also need to remember that we are still only looking at the 200 most widely spoken languages – many more languages and communities will be affected by this language exclusion than is apparent from these numbers.
| Language | Region | Country | First-language speakers | Second-language speakers |
|---|---|---|---|---|
| Chinese, Jinyu | Eastern Asia | China | 46,900,000 | 46,900,000 |
| Arabic, Sa’idi Spoken | Northern Africa | Egypt | 22,400,000 | 22,400,000 |
| Magahi | Southern Asia | India | 20,735,600 | 20,746,400 |
| Saraiki | Southern Asia | Pakistan | 20,009,000 | 20,009,000 |
| Chhattisgarhi | Southern Asia | India | 16,300,000 | 16,300,000 |
| Arabic, Mesopotamian Spoken | Western Asia | Iraq | 15,655,900 | 15,655,900 |
| Thai, Northeastern | South-Eastern Asia | Thailand | 15,000,000 | 15,000,000 |
| Arabic, Hijazi Spoken | Western Asia | Saudi Arabia | 14,524,500 | 14,524,500 |
| Chittagonian | Southern Asia | Bangladesh | 13,000,000 | 13,000,000 |
| Deccan | Southern Asia | India | 12,800,000 | 12,800,000 |
| Jula | Western Africa | Côte d’Ivoire | 2,208,000 | 12,486,000 |
| Sadri | Southern Asia | India | 5,131,180 | 12,131,225 |
| Pidgin, Cameroon | Middle Africa | Cameroon | 12,000,000 | |
| Sylheti | Southern Asia | Bangladesh | 10,300,000 | 11,800,000 |
| Arabic, South Levantine Spoken | Western Asia | Jordan | 11,601,100 | 11,601,100 |
| Arabic, Sanaani Spoken | Western Asia | Yemen | 11,350,000 | 11,350,000 |
| Chinese, Min Bei | Eastern Asia | China | 11,015,200 | 11,015,200 |
| Pashto, Southern | Southern Asia | Afghanistan | 10,878,800 | 10,878,800 |
| Rangpuri | Southern Asia | Bangladesh | 10,476,000 | 10,801,000 |
| Arabic, Ta’izzi-Adeni Spoken | Western Asia | Yemen | 10,533,300 | 10,533,300 |
Regional focus: Africa
Which African languages are more or less well-supported? The Ethnologue 200 lists 64 languages as African languages, which account for 650 million first-language speakers of African languages – or half the African population. The remainder likely either speak smaller regional languages or European-colonial languages as their first language. Using Ethnologue’s language survey as a basis, we can estimate which African language communities might need to switch to another language to use particular platforms – perhaps another major African language like Arabic, Swahili, or Somali, or a European-colonial language.
We will first look at platform support for the languages of North Africa and the Middle East, and then the languages of Sub-Saharan Africa.
North Africa and Middle East
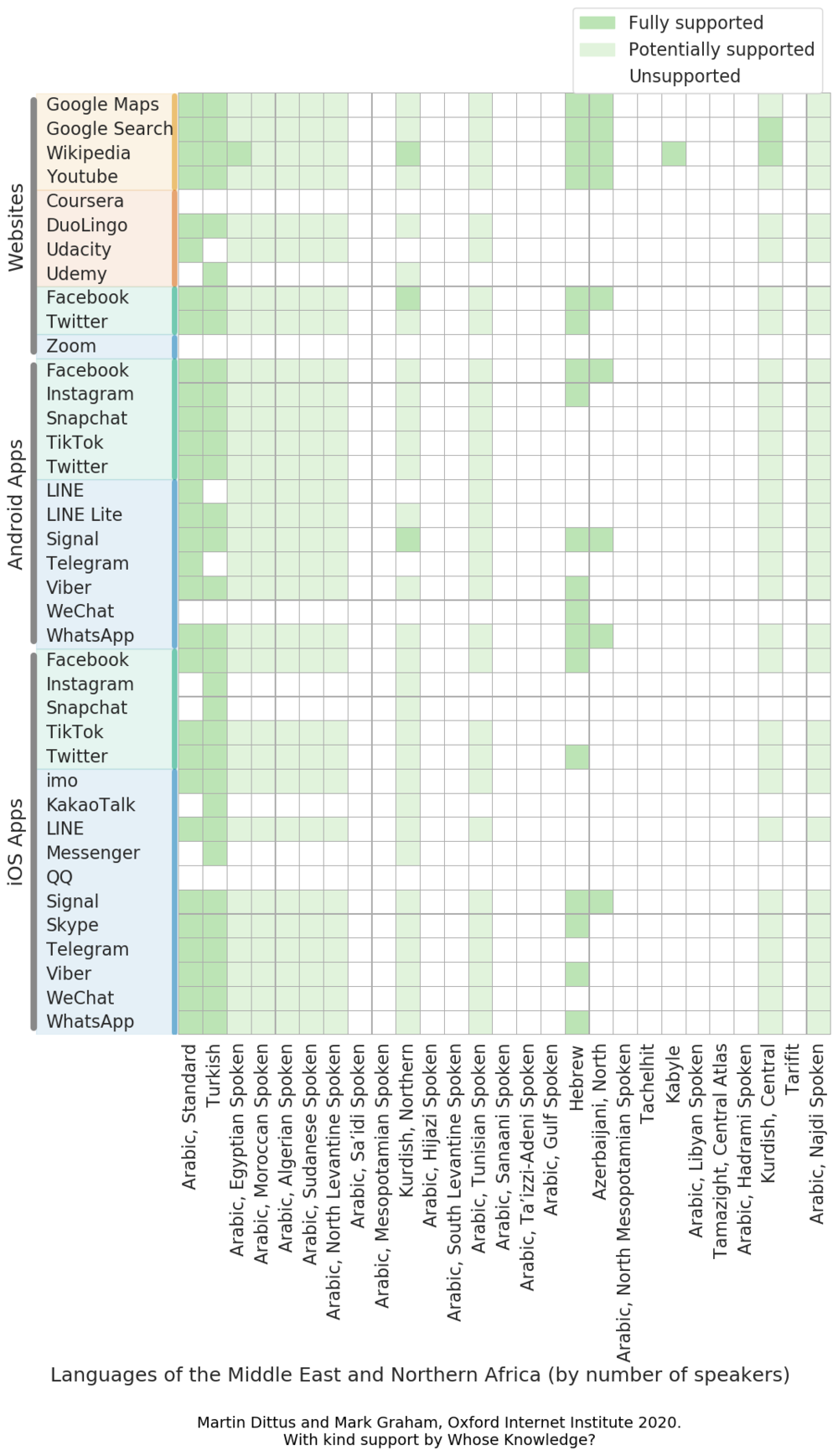
The Ethnologue 200 lists 27 North African and Middle Eastern languages, many of which are dialects of Arabic. We show the outcomes of our platform survey for these languages in Figure 5. Compared to the global overview we can see that there is much less support available overall – instead, it appears that most of the languages of the region are not supported by most of the platforms we surveyed.
It is particularly striking to see that none of the major Berber languages are supported by any of the platforms we surveyed – Tachelhit, Kabyle, Tamazight, and Tarifit are each spoken by millions, yet they are not available as interface languages anywhere, with the sole exception of the Kabyle language edition of Wikipedia.
A key presence in the region are the many Arabic dialects – the Ethnologue 200 includes its standard written form (Modern Standard Arabic) as well as 18 regional spoken variants such as Egyptian Moroccan, Sudanese, Tunisian, and Hadrami Arabic. The spoken dialects are generally not supported as interface languages on most of the platforms we surveyed, instead many platform operators offer their interfaces in Modern Standard Arabic (or what they often simply call “Arabic”.) To a non-Arabic speaker this might appear like a sufficient form of language support that conveniently captures an entire region, however speakers of Arabic know that the reality is more complicated – we have already hinted at some of the tensions with this approach. Broadly speaking, Modern Standard Arabic is a variant of the Arabic language that is used in formal writing and in public media, however it is rarely used in everyday informal communication. This does not quite give it the status of a foreign language, but it clearly distinguishes it from the spoken Arabic dialects that are much more present in everyday use. Importantly, for many Arabic speakers it is a language form that needs to be learned first – and it can diverge quite significantly from one’s own spoken dialect. As a consequence, Arabic-language speakers are much less well-supported than it might appear. We can see this reflected in the visualisation: for certain dialects the Unicode language distance measure offers Modern Standard Arabic as a potentially suitable substitute, while for others the dialects appear too far apart. From a perspective of cultural identity, the formal nature of Modern Standard Arabic also potentially makes any digital platform a somewhat alien space, and there are growing efforts to increase the online presence of other Arabic dialects.
Compared to these, the Middle Eastern languages Turkish, Hebrew, and to an extent Azerbaijani are relatively well-supported, and several of the larger platforms offer support for Kurdish dialects, however Kurdish and Azerbaijani are still much less widely supported than Turkish or Hebrew.
Sub-Saharan Africa
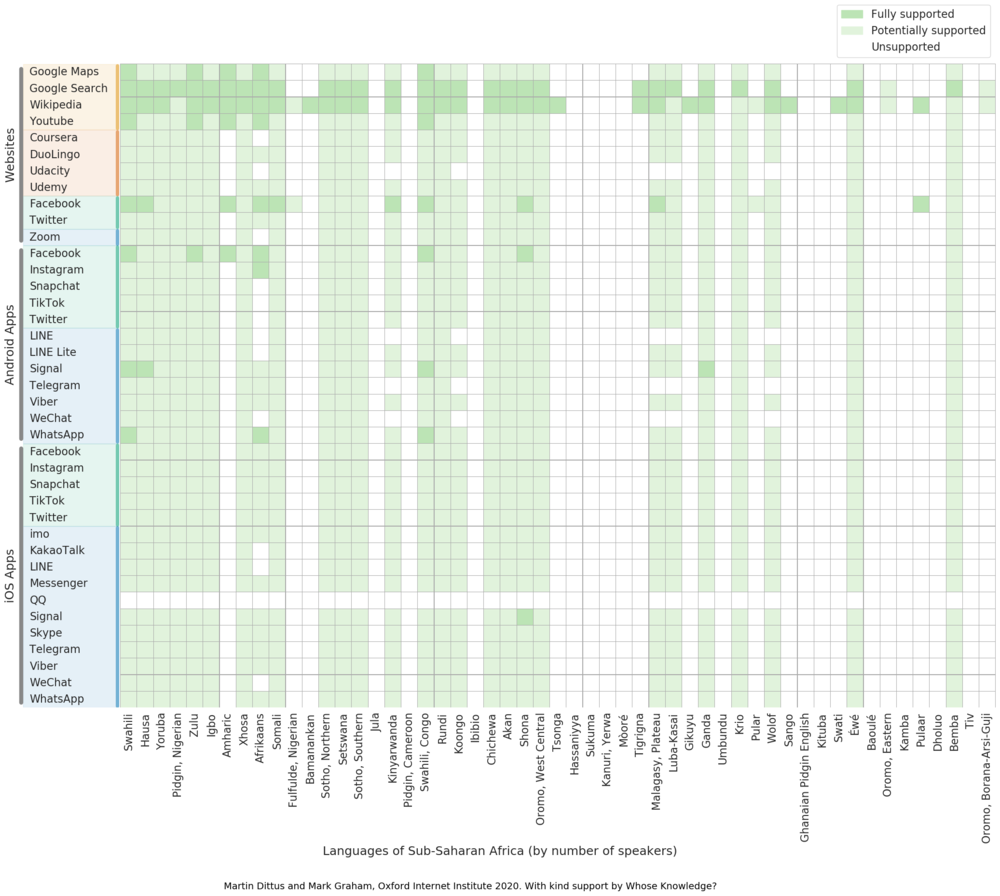
Ethnologue lists 53 languages of Sub-Saharan Africa in its list of the 200 most widely spoken languages, and we can see the results of our platform survey for these languages in Figure 6. Similar to the map of North Africa, we can see that platform support for Sub-Saharan languages is much less widespread than for other regions.
Certain major Sub-Saharan languages are directly supported as interface languages by some the largest platforms – languages such as Swahili, Hausa, Yoruba, Zulu, Amharic and many others are supported by both Google Search and Wikipedia, and further language support for a small subset of languages is offered by Google Maps, YouTube, Facebook, and Signal. Wikipedia and Google Search generally stand out in their remarkable presence, each offering full interface language support for more than half the Sub-Saharan languages in our sample. Compared to them, most other languages we surveyed are virtually absent.
In general we find that language support for Sub-Saharan languages is quite poor. While many languages are marked as “potentially supported” in Figure 6, this classification is misleading. In all of these cases, the Unicode language matching algorithm offers us English or another language of European-colonial origin as a suitable substitute language in order to achieve this level of support. In other words, the measure claims that the speakers of African languages such as Swahili, Yoruba, Hausa, Nigerian Pijin, Zulu, Igbo, Xhosa, and many others are likely to able to use an English-language interface. This might reflect the way language is used in practice – no doubt many speakers of Yoruba are also able to speak English. However, they are distinctly different languages, and from a linguistic, cultural, and political perspective we would not consider an English-language interface a successful instance of Yoruba language support.
In other words, when assessing African languages, the Unicode language matching algorithm is insufficient for a complete assessment, and we always also need to review the actual individual language relationships in order to make a proper assessment. And from the broad vantage point of these major African languages like Swahili, Yoruba, Hausa, and many others, support for African languages is actually quite poor: most platforms we surveyed do not support a single language of Sub-Saharan Africa.
Combined with the relatively poor coverage for North African languages and Arabic dialects, this means that most of the platforms we surveyed do not provide first-language interface support for more than 90% of all Africans, who instead need to switch to a second language in order to use the platform. And even platforms with comparatively good language support like Google Search and Wikipedia exclude almost half the African population on the basis of primary language.
The overall impression here is quite remarkable: most African languages are not supported at all by most of the platforms we surveyed, which means the majority of Africans are forced to use secondary languages – and for many this may mean using an European-colonial language.
Regional focus: South and South-East Asia
Which Asian languages are well-supported? Prompted by the patterns we saw earlier we are particularly interested in South- and South-East Asia, and will consider them in turn.
South Asia
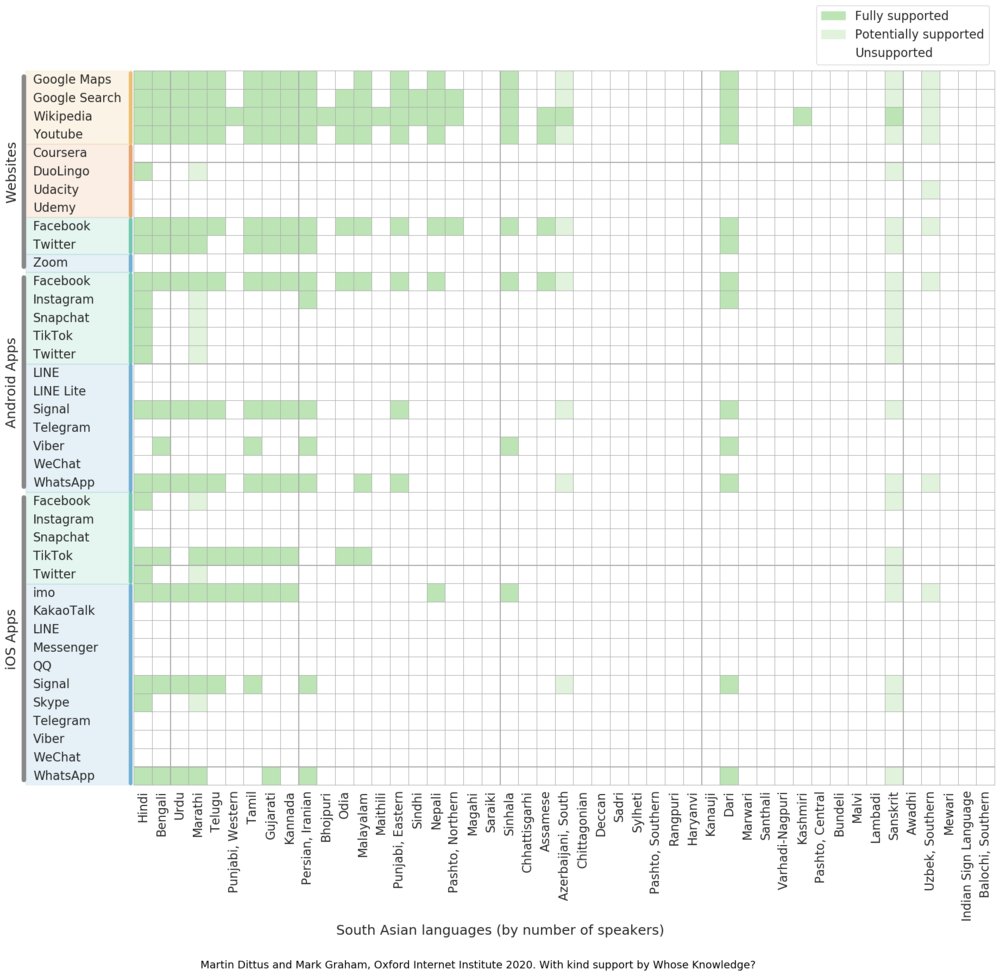
Ethnologue lists 47 South Asian languages in its list of 200 most widely spoken languages, which are shown in Figure 7. Overall we can see that most South-Asian languages are either not well-supported, or not supported at all.
It is worth pointing out that the most widely spoken South Asian languages tend to be supported by the major platforms to varying degrees – Google, Wikipedia, Facebook, Twitter, Signal and some others offer interface support for Hindi, Bengali, Urdu, Marathi, Telugu, Punjabi, Tamil, Gujarati, Kannada, and Persian. Messaging apps Signal, WhatsApp, and imo in particular cater to several of the more widely spoken South Asian languages, as do social media platforms Facebook, Twitter, and TikTok – in Figure 7 these platforms are visible as horizontal stripes.
However, almost half of the platforms we surveyed do not offer interface support for any of the major South Asian languages. As a result, South Asian languages are generally less widely supported than many of the European languages we looked at in our initial global overview.
Among the larger South Asian languages it is further notable that Punjabi in particular is comparatively undersupported, relative to other regional languages of its size. Only three platforms offer support for its widely spoken Western dialect: Wikipedia, Twitter, and the messaging app imo.
Support for smaller South Asian languages drops off quickly, and languages such as Odia, Mathili, Nepali, Sinhala, and Assamese are usually only supported by the major platforms, if at all. Many other South Asian languages, spoken by millions of people, are entirely unsupported by any of the platforms we surveyed.
South-East Asia
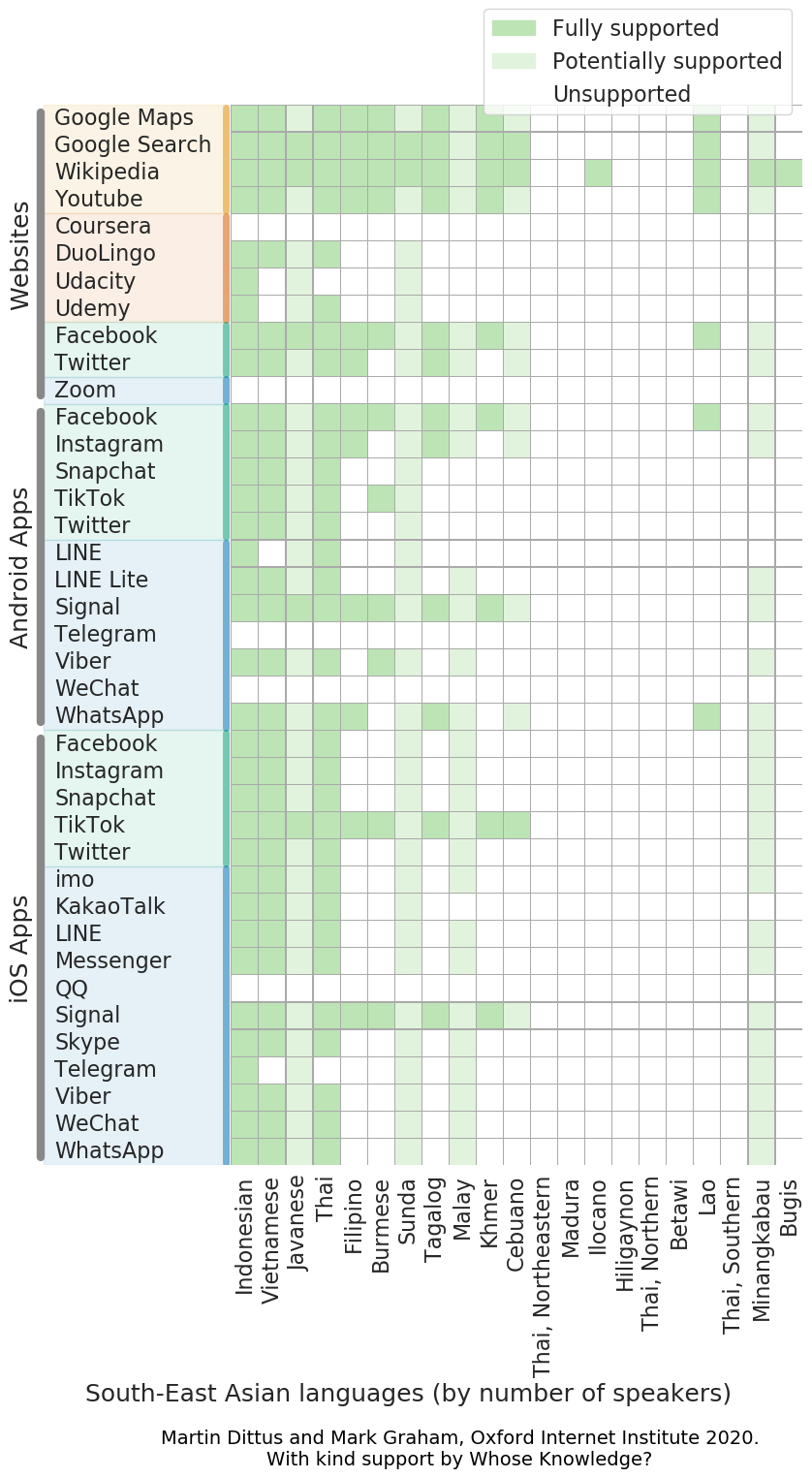
21 South-East Asian languages are identified in the Ethnologue 200, and their survey results are shown in Figure 8. Here too we can see that the most widely spoken languages of the region are generally more widely supported as interface languages, especially Indonesian, Vietnamese, and Thai.
Some complexities arise in assessing the matter of language support for Malay languages, a language with a large number of regional variants. The overall picture is somewhat more complicated that it may appear on our chart, in part due to the limits of conventional Western language classification which has historically distinguished languages of the region based on geography and ethnicity, rather than on their linguistic properties. In practice, the Malay spoken by people in Indonesia differs from Malaysian, Minangkabau, Brunei Malay, Jambi Malay, and other variants of the language. As a result it is not possible to provide a good assessment of the platform support for these languages based on the data we have collected. We can say that language support is likely less comprehensive than it may appear. Many websites we surveyed claim they support “Malay”, which is the name given to the macrolanguage, however this does not mean that the speakers of individual language variants will see themselves reflected in the offered translations. We would need to review the actual interface translations for every platform in order to assess which regional populations would see themselves reflected in which particular translations.
Most platforms do not offer direct interface language support for Sunda and Javanese, however the Unicode language distance measure suggests Indonesian as a potential alternative. In both cases there is some likelihood that speakers of these languages also do speak Indonesian as a secondary language, however the languages are quite different. In other words, here too the Unicode classification introduces some further potentially misleading assertions, and platform support for these languages is not as good as it may first appear.
Overall we can see that support for South-East Asian languages is largely limited to Indonesian, Vietnamese, and Thai which tend to be well-supported by the platforms we surveyed, and which are more widely supported than any of the South Asian languages. There is some further support for speakers of Malay languages, however it is likely less comprehensive than it may first appear. Overall, most South-East Asian languages are not supported by most platforms.
Discussion
Language support across the surveyed platforms
Major web platforms like Wikipedia, Google Search, and Facebook are at the forefront of language support, each offering interface support for more than 100 languages. Among them, the non-profit Wikipedia stands out as the most comprehensively translated platform by far, with a total of almost 300 supported interface languages, followed by Google Search with 150 languages. Among messaging apps the open source mobile app Signal has the most comprehensive language support, having been translated into almost 70 languages on Android, and more than 50 on iOS.
However, many of the platforms we surveyed only support around 10-30 of the thousands of languages spoken today. Most platforms focus their support on more widely spoken languages, and the majority of languages spoken today remain unsupported – we go into more detail below. This means that depending on the platform, as much as half the global population will be left out on the basis of their primary language. Even Wikipedia and Google Search still potentially exclude a billion people or more on the basis of their language. These excluded populations have to be able to speak a second language in order to be able to use and participate in these platforms.
The language-learning platforms we surveyed here were specifically chosen because they cater to self-guided and informal language learning. It emerges that interface language support for these platforms is largely limited to a small number of major (and Western) languages, possibly reflecting the significant effort required to translate a full curriculum to a new language – in contrast to messaging platforms, education platforms also need to translate their content in order to provide proper language support. We should note that there are many additional language learning platforms that cater to speakers of specific languages, however they commonly integrate into more formal learning structures such as the respective national curriculum. This includes education platforms in India and China such as KnowBox, BYJU, Yuanfudao and others.
A small number of languages are very widely supported
A small number of languages tend to be very widely supported by the platforms we surveyed. This includes many of the European languages, especially English, Spanish, Portuguese, French, German, Italian, and Russian, however also certain Asian languages, especially Mandarin Chinese, Indonesian, Japanese, Korean, and Thai.
We also found that certain widely spoken languages are not as well supported as might first appear. This is especially true for Arabic. Platform operators commonly offer Modern Standard Arabic support for their interfaces, which diverges quite significantly from many of the spoken Arabic dialects that are much more common in everyday use. Similarly, many platforms offer translations in Malay, but it is typically not made clear which of the different variants of this language is being offered.
Beyond these major languages, others spoken by tens to hundreds of millions are highly unequally represented in terms of both interface support and content availability. We see digital exclusion especially of African and South Asian languages, and will discuss these in more detail next.
Digital exclusion of most African languages
We have already mentioned the common issues with Arabic-language support. Among the North African languages it is further notable that we have seen an almost complete absence of support for Berber languages, representing tens of millions of people.
Some of the largest platforms support the major Sub-Saharan languages Swahili, Yoruba, Hausa as interface languages, however in general we find that language support for Sub-Saharan languages is quite poor, and most platforms we surveyed do not support a single Sub-Saharan language.
Overall this means that most of the platforms we surveyed do not provide first-language access for more than 90% of all Africans, who instead need to switch to a second language in order to use the platform – for many this may mean a European-colonial language.
Unequal support for South and South-East Asian languages
We find that South Asian languages are less widely supported than other major languages that are spoken by a similar number of people. The more widely spoken languages like Hindi, Bengali, Urdu, Marathi, and Gujarati are generally well-supported by major platforms like Google, Wikipedia, and Facebook. However major languages such as Hindi and Bengali, spoken by hundreds of millions of people, are generally less well-supported than some other languages of comparable population size, particularly the very widely supported European languages. Almost half of the platforms we surveyed do not offer interface support for any of the major languages in the region.
It is notable that Punjabi in particular is comparatively undersupported, relative to other regional languages of its size. Only three platforms offer support for its widely spoken Western dialect: Wikipedia, Twitter, and the messaging app imo.
Support for South-East Asian languages is similarly mixed: Indonesian, Vietnamese, and Thai tend to be very well-supported by the platforms we surveyed, however most other South-East Asian languages are not supported by most of the platforms we surveyed. There is some support for speakers of Malay languages, however due to the linguistic diversity within this language it is likely less comprehensive than it may first appear.
Interpretation
Overall we can see that language support is highly unequally distributed among the world’s 200 most widely spoken languages. The clear unequal geographies of language support may on the surface look like a Global North-South divide, where language support appears to be much better among the language communities of the Global North, notably Europe and Asia. However, a closer look reveals patterns of marginalisation within each of the regions we looked at. Among the most widely spoken languages globally, Hindi, Bengali and Urdu are prominently undersupported. Within Europe, Eastern European languages are potentially undersupported. Within Asia, Central and South Asian languages are comparatively unsupported. Within South-East Asian languages, all except the main three regional languages are also comparatively unsupported. This kind of layering indicates the potential presence of a systemic logic of exclusion, rather than a simple geographic North-South divide: for example, it may be the result of market forces bearing on the decision of whether to spend money supporting particular markets.
We also have to acknowledge the relatively limited scope of this first platform survey, for example the inherent biases embedded in our platform selection. Many of the platforms that have an (arguably) global reach originate in Western and Anglo-centric cultures, and often stand in the tradition of Silicon Valley culture, which is further reflected in their language coverage. However, a growing ecosystem of platforms is catering to specific languages and regions far outside these narrow cultural frames, and this wealth of new platforms is not yet reflected in our survey. As an entry point into a broader view we have made an attempt to cover the ecosystem of messaging apps more comprehensively, given it is a sector where people use quite different apps in different parts of the world, however there still are many opportunities to improve our platform coverage in future reports.
Related articles in this report
Unfortunately, in this platform survey we did not have sufficient data about languages that originate in the Americas and the Pacific. However, the essays by Jeffery and Ashley, Ana, and the Kimeltuwe Project can offer some perspective on the digital experiences of language communities in the Americas. Their testimonies suggest that the languages originating in the region are commonly not well-supported on the internet.
If we extend our view beyond interface support and also look at the content available in particular languages we can see that major languages such as Indonesian, Hindi and Bengali are subject to further digital exclusion. In our content analyses of Google Maps and of Wikipedia we find that digital content is not always available in these languages. Instead, people speaking these languages might find that their Wikipedia language edition is significantly less comprehensive than English Wikipedia, or they may find on Google Maps that the interface is offered in their language, but the map is in English. Ishan’s Paska’s essays offer us some further lived experience on the lack of content in Bengali and Indonesian.
Bibliography
-
Eberhard, David M., Gary F. Simons, and Charles D. Fennig. 2020. ‘Ethnologue: Languages of the World’. Twenty-third edition. Dallas, Texas: SIL International. http://www.ethnologue.com/ ↩︎
-
Unicode. 2020. ‘Unicode Common Locale Data Repository’. 37. http://cldr.unicode.org/ ↩︎